Semantic visual objects relationship detection
Tech, data & sensors:
Image data
Customizations:
Attention, Multiple Modalities, Translation Embeddings, Deep Supervision.
Challenges in Semantic Visual Relationships: Is this “pizza slice on the plate” or “next to the plate?”
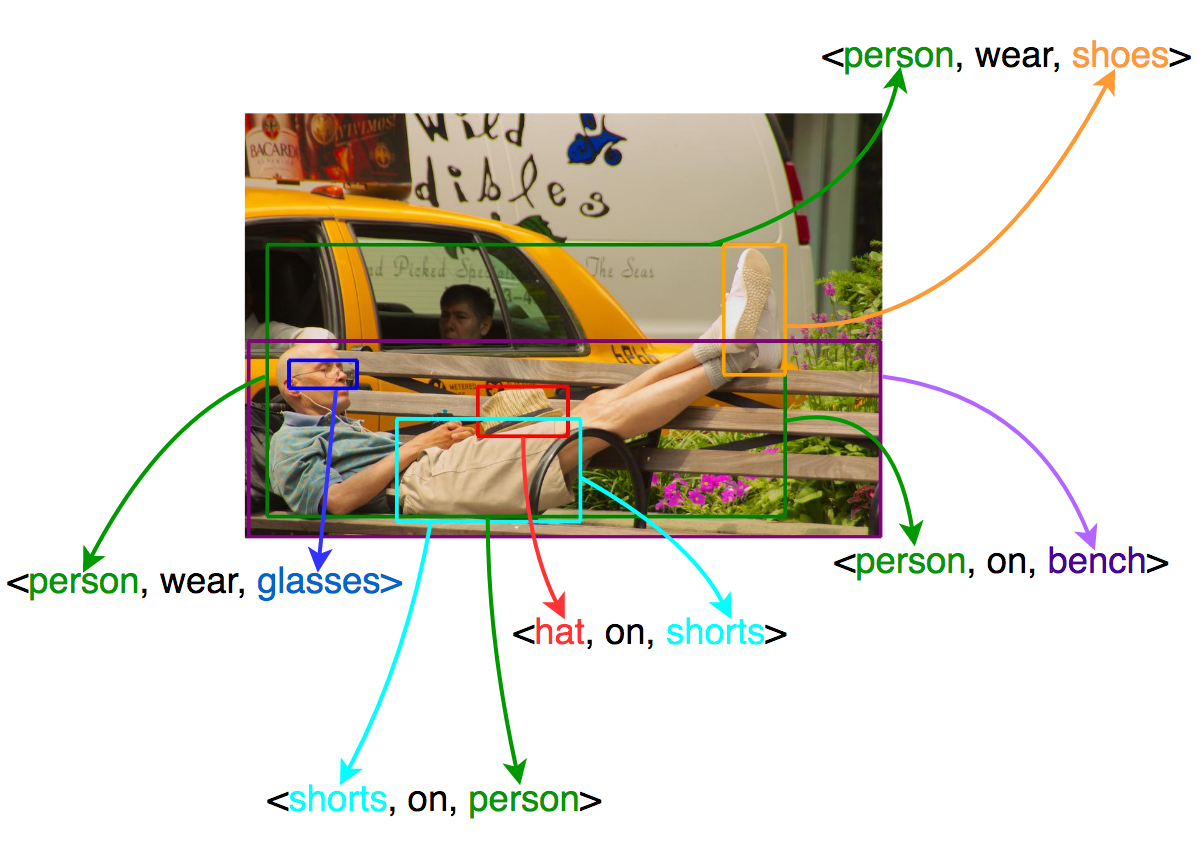
Is this “pizza slice on the plate” or “next to the plate?” The classification of such semantic visual relationships, namely Visual Relationship Detection, aims on bridging the gap between visual and semantic perception by detecting < S, P, O > triplets, with the predicate P being the relationship of subject S and object O, e.g. “pizza – on – plate” (See figure bellow). Visual Relationship Detection is a useful task towards an advanced machine perception: it can be seen as a basic parsing of the image, that creates the syntactic structure a high-level machine would use to infer knowledge. The task is challenging and open in the literature: in addition to the difficulties of Object Detection, the number of possible relationships is exponential and their visual variability is quite large. In the figure above for example, the 8 objects that are detected can yield 8*7 = 56 possible combinations and even those with the same relationship class – e.g. “behind” on “bottle – behind – pizza” and “chair – behind – table” – are drastically different in terms of appearance.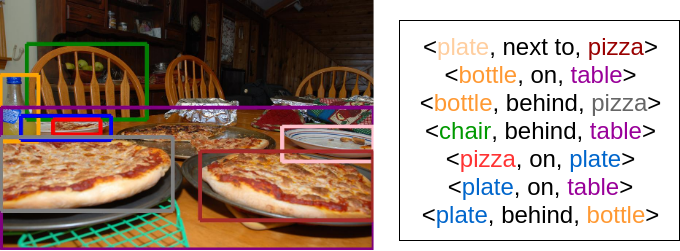
Solution
Inspired by the complementary nature of language and vision, knowledge representation as translation embeddings, recent advances in attention mechanisms and Deep Supervision, we introduce Multimodal Attentional Translation Embeddings (MATransE): Given a detected subject-object pair, MATransE employs spatial and linguistic information in an attention module (SLA-M) that guides the classification of the convolutional features of the subject (orange), object (green) and predicate box (purple);See block diagram on top. Subject-object and predicate features are handled into two separate branches, OS-Branch and P-Branch respectively, and their scores are fused. The single branches and their fusion all contribute to the total loss and are jointly optimized with Deep Supervision, forcing an alignment in the score space such that P ≈ O − S.Results
MATransE is scalable to detect thousands of relationships by learning to predict each component (S, P and O) separately. Motivated by the successful formulation of Zhang et al. that project S, P, O in a space where S + P ≈ O, our system learns three projection matrices and employs a Spatio-Linguistic Attention module that uses binary masks’ convolutional features and subject-object embeddings, to guide the visual appearance features. We jointly train two branches, and employ Deep Supervision. We compare our approach to prior works on the widely used VRD dataset. The evaluation metric is Recall k @x (R k @x). Let N be the number of examined subject-object pairs in an image; then, keeping the top-k predictions per pair, R k @x examines the x most confident predictions out of N k total. Commonly used values for k and x are (1, 70) and (50, 100) respectively. Under these metric settings, MATransE achieves a new state-of-the-art, outperforming prior results: Comparisons using R1@50 show that we achieve 0.43%, 2.41% and 4.76% respective relative improvement over the main competitors. Using R70@100 still MATransE achieves 32%, 40.1% and 45.8% relative error decrease.
Publications
- N. Gkanatsios, V. Pitsikalis, P. Koutras, A. Zlatintsi, P. Maragos, “Deeply Supervised Multimodal Attentional Translation Embeddings for Visual Relationship Detection”, In Proc. ICIP, 2019 PDF
- N. Gkanatsios, V. Pitsikalis, P. Koutras, A. Zlatintsi and P. Maragos, “Showcasing Deeply Supervised Multimodal Attentional Translation Embeddings: a Demo for Visual Relationship Detection”, In Proc. ICIP, 2019 Link
- N Gkanatsios, V Pitsikalis, P Koutras, P Maragos, “Attention-Translation-Relation Network for Scalable Scene Graph Generation”, In Proc. ICCV Workshops, 2019, PDF
- N Gkanatsios, V Pitsikalis, P Maragos, “From Saturation to Zero-Shot Visual Relationship Detection Using Local Context”, In Proc. BMVC, 2020, PDF